Thanks to our many years of experience testing components, vehicles, and platforms, we know that as vehicles have become more complex, so too have the demands placed on vehicle testing and test drivers. Test drivers face the challenge of documenting issues in as much detail as possible during test drives, completing the drives in a timely manner, and—of course—arriving safely at their destination.
Our AI-powered co-pilot ensures high-quality, real-time information exchange without any data loss. The driver exchanges relevant information with the AI through natural dialogue: driving maneuvers are guided and documented; during the test drive, anomalies are recorded, details are logged along a fault tree, and the data is documented in real time within the test systems.
Our AI-powered co-pilot significantly improves data quality while reducing the driver’s workload and thereby enhancing safety, all while increasing processing speed and lowering costs.
“We receive hundreds of calls a day, and especially during these extraordinary times, the support provided by SUSI is invaluable. She offers us significant added value.” Our digital assistant, SUSI, handles incoming calls at Dr. Eckermann and Bauer’s medical practice. She records the concerns of callers and prepares the information for the staff.
“This AI solution takes some of the load off our staff, and our practice is always available to callers. That gives us a great sense of satisfaction.”
Because the value-added processes of modern supply chains are synchronized, disruptions to normal logistics operations result in significant costs, lost time, and consequential expenses—often extending throughout the entire supply chain all the way to product delivery. Since disruptions occur time and again despite a zero-defect approach, it is crucial to identify problems quickly and comprehensively in order to generate a targeted solution in the short term and put it into practice.
This is where our AI really shines. With SUSI, issues can be reported 24/7 through natural conversation. Whether by phone or chat, it identifies the problem, conducts a dynamic troubleshooting dialogue, documents the issue in the customer system, and triggers workflows in real time. As a result, delivery delays are transparently and automatically accounted for, the process for handling shipping damage is automatically initiated, and short shipments are reported and reconciled.
Reporting issues is quick and easy, the data is complete, and—because SUSI is always running—it reliably shortens or completely prevents the duration of harmful special processes.
Today, smart intralogistics solutions are indispensable in production and warehousing. Goods must be efficiently integrated into supply chains, and shipments must be processed quickly. Our client, MFI Innovations, offers a wide range of individual and comprehensive solutions for these needs and uses our SmartOffice for its customer service hotline.
If an error occurs among MFI’s industrial customers, it can lead to critical intralogistics downtime at any time of day or night. Such outages can become very costly in the absence of support, which is why MFI Innovations offers its customers tailored service packages to ensure they are fully supported even in the event of a crisis.
When affected companies call MFI’s customer service, they will either be connected directly to a technical support specialist or, if one is not currently available, to our SmartOffice. There, they can immediately report the issue and any relevant error codes so that MFI Innovations can initiate its support process as quickly as possible.
As soon as the line is back up, the technical specialist can use the information already gathered to assess the situation, conduct a preliminary analysis, and, ideally, present a solution to the company during the very first callback.
Thanks to our many years of experience testing components, vehicles, and platforms, we know that as vehicles have become more complex, so too have the demands placed on vehicle testing and test drivers. Test drivers face the challenge of documenting issues in as much detail as possible during test drives, completing the drives in a timely manner, and—of course—arriving safely at their destination.
Our AI-powered co-pilots ensure high-quality, real-time information exchange without any data loss. The driver exchanges relevant information with the AI through natural dialogue: driving maneuvers are guided and documented; during the test drive, anomalies are recorded, details are logged along a fault tree, and the data is documented in real time within the test systems.
Our AI-powered co-pilots significantly improve data quality while reducing the workload on drivers and thereby enhancing safety, all while increasing process speed and reducing costs.
The volume of calls at law firms exceeds the availability of administrative staff. A particular challenge is that call volume is subject to cyclical fluctuations. As a result, many calls go unanswered during peak times. Without the SUSI, the Digital Assistant Secretaries had to take down the callers’ requests during time-consuming conversations and forward them in brief notes to the appropriate legal representative for processing.
Since the partnership began, SUSI has been assisting the secretariat staff. It handles all calls that the secretariat team cannot process. During the call, the caller states the reason for the call, and the AI classifies the issue. Depending on the identified issue, SUSI either asks specific follow-up questions or answers the caller’s question immediately.
It then sends a summary, including the requested case numbers, to the relevant department or directly to the legal representative in question. SUSI also informs the caller which documents can be sent to the law firm in advance. This reduces the number of follow-up calls and minimizes processing time.
The energy supply business is heavily influenced by seasonal events. Price increases, bill mailings, or new energy rate plans cause many customers to contact the energy supplier within a very short period of time. With a shortage of skilled workers and an already enormous workload, it is not always possible to handle the volume of incoming calls.
The digital assistant SUSI is part of the SmartOffice It has the necessary skills and experience to provide direct support to energy utilities and other public utilities. It handles all incoming calls and routes them based on the nature of the inquiry. In the case of critical issues, such as a gas outage, it forwards the call directly to the emergency dispatch center.
By automating the processing of meter readings, advance payment adjustments, and invoice changes, employees free up time that they can devote to more client-focused conversations with customers.
The artificial intelligence-based digital employee SUSI from SUSI & James GmbH takes over and optimizes a wide variety of communication-heavy business processes in companies. SUSI ensures 24/7 that no call goes unanswered and takes all calls. With its support, SUSI creates space and time for service-intensive issues. Employees can once again concentrate fully on value-adding activities.
In this article, we highlight the use of SUSI as a Digital Product Advisor.
We show how to combine traditional NLP with the power of LLMs and Generative AI in a way that ensures the best possible customer experience.
The following demo is about a consultation between a digital employee and a user who is interested in buying a new car. SUSI guides the user through a three-step process in which general information about the desired vehicle can first be provided. Then, based on a suggested selection of eligible vehicles, the user can learn more about these vehicles by asking specific questions. Once the user has decided on one or more vehicles, the last step is to arrange a test drive or a purchase appointment.
Step 0 — Preparing the data and make some basic considerations
The basis for product consulting are products, in this case about 7000 current vehicles, which are available in JSON format. (Displayed simplified in this example){ „name“: „A3“, „car_model_id“: 82, „car_trim_id“: 25295, „car_series_id“: 2901, „car_production_year“: „2016“, „car_series_name“: „Sportback Schrägheck 5-Tür“, „car_trim_name“: „1.2 TFSI MT (105 ps)“, „car_specifications“: { „Anzahl der Gänge“: „6“, „Schadstoffeinstufung“: „EURO V“, „Fahrzeugart“: „Schrägheck“, „Sitzplätze“: „5“, „Breite“: „1785“, „Radstand“: „2636“, „Spur vorne“: „1535“, „Kofferraumvolumen minimal“: „380“, „Kofferraumvolumen maximal“: „380“, „Spur hinten“: „1506“, „Kraftstoffe“: „Benzin“, „Hubraum“: „1197“, „Wendekreisdurchmesser“: „10.9“, „Zuladung“: „485“, „Anhängelast (gebremst)“: „3240“, „Ladehöhe“: „677“ }, „car_options“: { „Attraction“: [ „Elektromechanische Servolenkung mit variabler Kraft auf das lenkrad“, „Servotronic (aktives lenkrad)“, „Schallschutz Verglasungen“, „Start-stop-System“, „Mechanische Vordersitze einstellen“, ], „Ambiente“: […], „Ambition“: […] }, „manufacturer“: „Audi“ }
When developing a Retrieval or Retrieval Augmented Generation (RAG) approach for a dataset containing detailed car (or any other product) information, it’s crucial to consider various factors to ensure an effective and accurate system. Here’s a breakdown of the aspects to consider:
Understanding the Data Structure
Understanding the dataset’s structure is foundational. The given dataset is in a structured format with nested fields and especially mixed data types, which requires a clear understanding to accurately retrieve or generate the necessary information. Special consideration should be given to the fact that, depending on the heterogeneity of the data points, aspects such as the presence of contextual information,digits, and mixed data must be taken into account, especially when vectorizing.
Indexing Strategy
Proper indexing is crucial for effective retrieval. Consider using a robust indexing strategy to ensure quick and accurate retrieval of car details based on various parameters such as car model, production year, or manufacturer.
Query Formulation
The query formulation should be designed to handle a variety of search terms and parameters. It should be robust enough to accommodate different types of queries and return relevant results.
Retrieval-Augmented Generation
For RAG, integrating retrieval mechanisms with generation models requires a seamless flow of information. Ensure that the retrieval process can feed relevant data to the generation model to facilitate meaningful output. Special attention should also be paid here to the question of the target language, since capable LLMs do not function well multilingually in every case.
Evaluation Metrics
Establishing evaluation metrics is necessary to measure the performance of the retrieval and generation systems. Metrics could include accuracy, recall, precision, and F1 score among others. To perform a qualitative analysis of the entire scope, individual metrics are usually inadequate. Frameworks like Ragas can fill this gap.
Scalability
The system should be designed to handle scalability to accommodate growing data or increased query loads without compromising performance.
The Haystack framework and the SmartOffice form the basis for the above steps. In the example shown, it quickly becomes clear that an initial selection of vehicles to be proposed can and should be based on a number of metadata such as manufacturer, fuel consumption and number of seats.
Since a classic document is represented in Haystack as follows:class Document: content: Union[str, pd.DataFrame] content_type: Literal[„text“, „table“, „image“] id: str meta: Dict[str, Any] score: Optional[float] = None embedding: Optional[np.ndarray] = None id_hash_keys: Optional[List[str]] = None
the question quickly arises as to which JSON content is defined as content on which textual embeddings will later also be generated and which data will become part of the meta-data.
As for the choice of database (or DocumentStore), we compared Weaviate and ElasticSearch. Both systems offer similar advantages and disadvantages, especially the advanced filter logic in the case of ElasticSearch tipped the scales for prototyping.
Step 1 — Designing Prompts for Basic Retrieval
In this step, the focus is on the question of how to derive and extract from almost arbitrary natural language statements the criteria on which meaningful filtering can be performed.
Step 1: General description of the car and its parameters
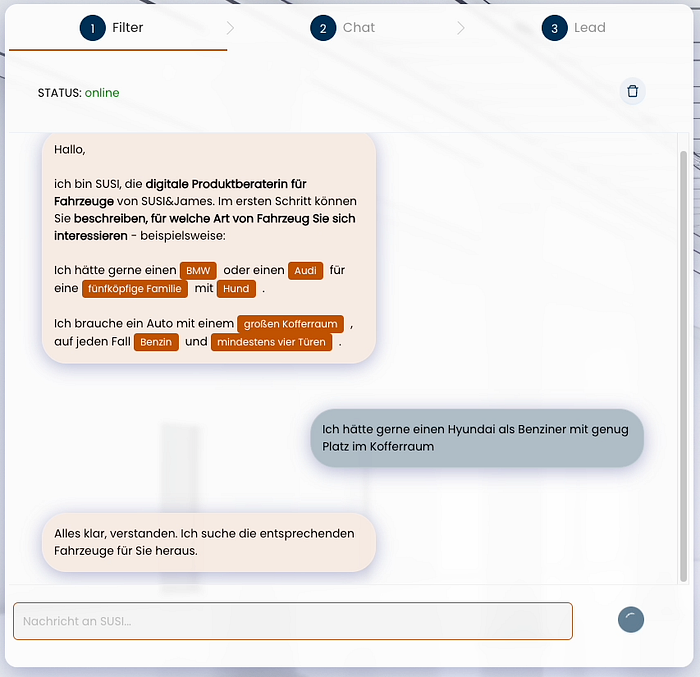
The statement pictured in SUSI’s introduction translates as:
„I’d like a BMW or an Audi for a family of five with a dog.“
The filter we need to construct from this in Haystack-compatible format looks like this:{ „$and“: { „number_of_seats“: { „$eq“: 5 }, „trunk_volume_minimum“: { „$gte“: 400 }, „manufacturer“: { „$in“: [ „BMW“, „Audi“ ] } } }
For this problem, we evaluated several approaches, including:
Text2SQL approach which refers to a type of natural language processing (NLP) approach that translates natural language queries into SQL (Structured Query Language) queries.
Span extraction approach which refers to a task in Natural Language Processing (NLP) where the goal is to identify and extract a specific portion of text, referred to as a “span,” from a larger body of text based on a given query or condition.
Generative approach which refers to the assumption that large language models given a specifying prompt have sufficient knowledge about identifying and extracting specific information from a given text to be able to satisfy the aforementioned requirement in the form of generated output.
After a short prototyping phase of the mentioned approaches, we decided to use the generative approach. The shortlisted models were:
After a prompt engineering phase, the following prompt proved to be a good fit (partially shown here):I need you to create a json serialized python dictionary as string that is derived from a user input.
In the user input there are filter criteria that can be expressed in different ways. The user can express himself on the following parameters:
The following logical operators are available: $and, $or
The following comparison operators are available: $eq, $in, $gt, $gte, $lt, $lte
The GPT-4 and Falcon-180B models have shown similar performance quality, which is why we have implemented both methods in a configurable way. The outcome looks like:
Step 1: Result with eligible cars bases on the user input
It should be mentioned that the biggest challenge was to get the models to reliably produce structured output in JSON format. In the meantime, there are various approaches to this problem, which we have not dealt with further in the scope of this processing. It should also be mentioned that while the LeoLM model did not quite provide the required result in this case, it has proven to be very capable in other experiments, such as extracting personal data from a text.
Step 2 — Designing Prompts for Advanced Retrieval and Question Answering
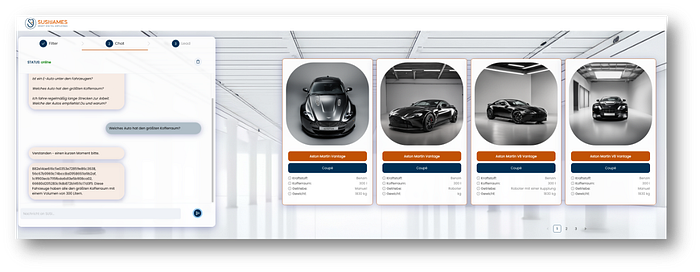
In this step, the focus is on a consultation regarding the pictured vehicles (and also additional ones not pictured). The user should intuitively and colloquially ask questions or discuss ideas that will help him/her select specific vehicles.
Step 2: Consultation regarding the pictured vehicles
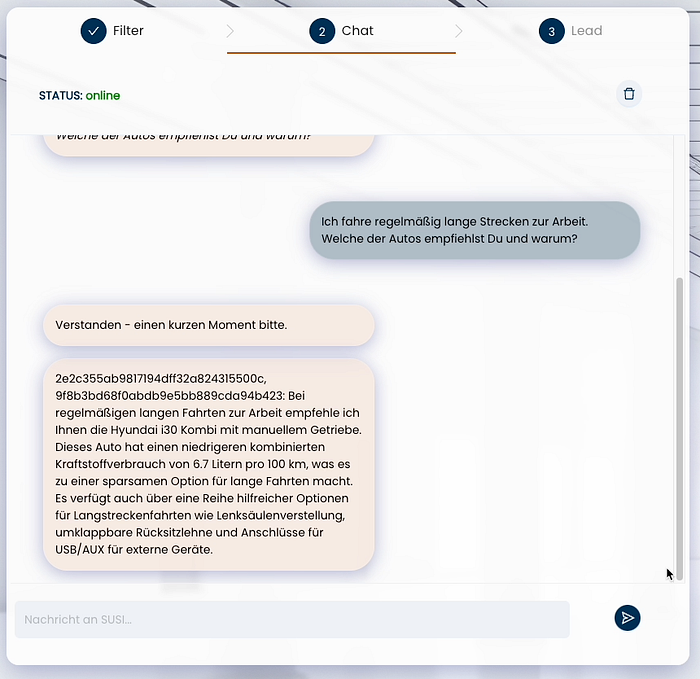
The statement pictured in SUSI’s introduction translates as:
“I regularly drive long distances to work. Which of the cars do you recommend and why?”
In this statement, representative of the presented form of expected user input, there are several challenges at once.
As already visible in Step 1, there is no parameter in the data basis that reads: “suitable_for_long_distances”. Even if there were, the question of qualification to this suitability would arise. The user’s expectation is different: “I don’t know exactly what parameters need to be considered to make a vehicle suitable for long trips, so I hope (or expect) that YOU know.”
In the second part of the statement, the user unconsciously (sometimes consciously) provides the context of the vehicles to be considered by using the term “of the (mentioned) cars”. At this point, we use the demonstrable power of the RAG procedures, in two ways:
We instantiate an agent that handles the communication with the user. The advantage of the agent is a persistent memory, which is made available as a previous conversation history to the processing of the user input. Thus, the model is aware of the context when referring to information in the previous conversation by the user.
We then give the agent various tools such as retrieving data from the Elastic Cluster and checking information on the Internet, and of course the basis of judgment: the vehicles and their data, and then try to let the model capture the relationship between the user input and the data at hand by clever prompting:Below you will find information about vehicles, such as their length, weight and equipment. Each vehicle has its own line and each line begins with the vehicle id. The information has the scheme „attribute_descriptor: attribute_value;“ except for the options. These are under „Optionen“ and are listed as packages with the schema „_package_descriptor_: list_of_comma_separated_attributes“. {car_description} Under the vehicle information you will find the question of a user. Answer the question as best you can, based solely on the vehicle information. Write the answer in German. If you can’t find the answer based on the information, please let us know. Every answer should have the format: „vehicle_id (or vehicle_ids comma separated): textual_response“, except if the user expresses an interest in buying or test driving the product, you will output „%smartoffice#vehicle_id or comma separated vehicle_ids#kind_of_interest%“ (where kind_of_interest is either test_drive or buy_vehicle) as the response. It is possible that the user asks questions or statements with a reference to the previous course of the conversation, which you can find here: {history} Your answers should take this conversation history into account, if appropriate and necessary. Question: {query} Response:
Step 2: Response from the RAG approach
The response in the image translates to:
“For regular long trips to work, I recommend the Hyundai i30 station wagon with manual transmission. This car has a low combined fuel consumption of 6.7 liters per 100km, which makes it an economical option for long trips. It also has a number of helpful options for long distance driving such as steering column adjustment, folding rear seat back and ports for USB/Aux for external devices.”
This is exactly the behavior that we hope for or imagine from our digital employees. The response not only addresses the focus of the user’s input, but also provides additional information that is considered helpful to the user.
This time the result was more difficult to judge. While GPT-4 stood out positively in terms of “consulting performance”, the interpretation of user input in terms of “parameters to be taken into account” or the direct answering of questions was clearly better in Falcon-180B from our point of view.
Step 2: Follow up questions to a given set of cars
The difficulty was, and still is, primarily in correctly capturing the task that is generated from the interpretation of the user input and letting it flow into the prompt.
The question and the response in the image translate to:
Q: “Which of the vehicles has the largest trunk?”
A: “These vehicles have the largest trunk with a volume of 300 liters.”
Similar to the example just given, there is an implicit reference to the vehicles defined as the result set in the previous step. The character of the user’s question is reminiscent of a classic example of automated question answering. The complexity of the question is much lower than the previous one because of the level of inference we expect from the model in terms of deliberative conversation.
Step 3 — Handing over to the SmartOffice
At this step, the user has gone through the process to the point where there is either an interest in purchasing or an interest in test driving one of the vehicles. At this point, one could rightly think about the further use of an agent-based solution, but in the corporate context we rely on our SmartOffice product, as it already solves a large part of the existing challenges in a sensible and efficient way.
Step 3: Handover of the user to the guided dialog
The introduction in the image translates to:
“Hello,
I am SUSI, the digital employee of SUSI&james car dealership. I understand that this is about a test drive of the vehicles “Huyndai i40 1.6 MT (135HP)”. In the following I need to ask some personal information for this.
Do you agree with this?”
The conversation then continues as follows:
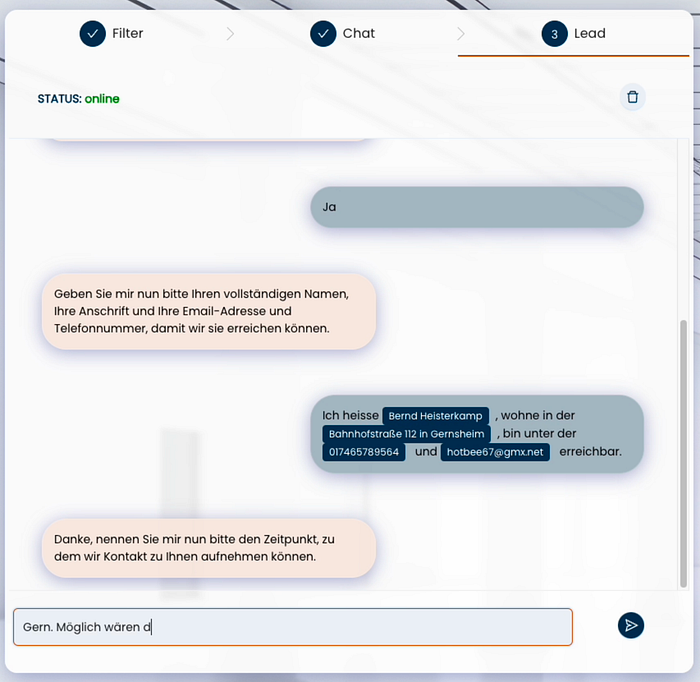
Step 3: Continuous processing through the SmartOffice
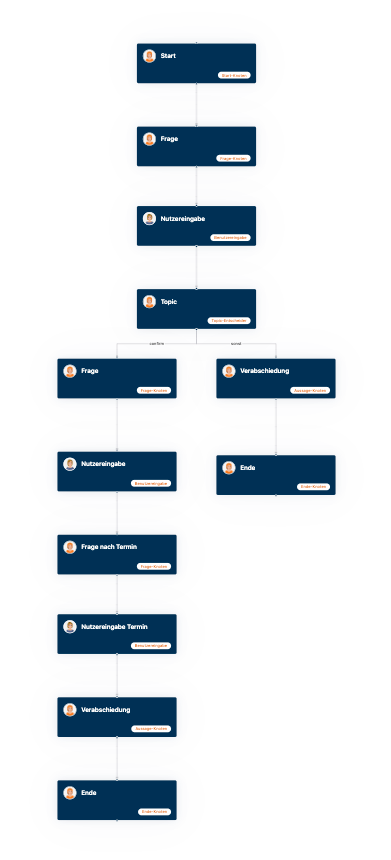
SUSI in SmartOffice needs to collect various information to make an appointment for a test drive. This information is requested in the course of the conversation, and queries are asked if necessary. In this case, this is not not done by an “autonomous” agent, but around the NLU core of the SmartOffice, orchestrated by predefined dialogs, as shown in the following image:
Step 3: A dialog created with the DialogBuilder of SmartOffice
SmartOffice processes all the information obtained during the call and can subsequently provide it for further processing in various ways, e.g. in the form of an API call, a mail or an outgoing call.
The path shows how a consultation with predefined interest can turn into a potent lead in a sales pipeline. For reasons of comprehensibility, the procedure shown is divided into several steps. It is of course also conceivable (and we have also evaluated this) to greatly simplify this process.
Learnings
In our view, the topic of product advice is challenging even in the very current technology space with Question Answering, Retrieval Augmented Generation, Autonomous Agents and Conversational AI. The main reason for this is certainly that we are not dealing with classic, general conversations with a simple question-answer process, but with complex, multi-layered dialog logic.
The following striking features and learnings are worth mentioning at this point:
Modular architecture based on LLM
When designing the product consultation, we wanted to take into account that the product base may change. In one case it might be vehicles, in the next it could be medicines or beauty products. For this reason, all components that are use-case specific are designed as modules (the database, the prompts, …), so that an exchange and an adaptation are possible intuitively and with little time effort.
LLM vs “traditional approaches”
In the steps shown, it was obvious not to commit to a single technology approach, but to decide in a fine-grained way which solution path is suitable for which problem. While “traditional” approaches such as entity extraction and possibly even syntax parsing promise a certain degree of security through reproducibility and control, they are relatively costly — for example, due to the use-case specific adaptations. Using Large Language Models, on the other hand, works intuitively even in the first approach, and if you have either the hardware or the necessary financial resources, you will have qualitative results very quickly. In fact, one should not make the mistake of considering the topic of “prompt engineering” as “solved”. Even minor changes decide the value of the output and should be well considered. In addition, the currently popular question arises in any case whether one should finetune an LLM in relation to the usecase or whether one should choose a RAG approach, for example. Here, too, requirements such as a clean data basis, training resources and time quickly pose a hurdle.
Unpredictability of user input
During the testing of the system shown and also of SmartOffice in general, we noticed that we often only think we know what the concerns of users are and that we can only assume what inputs in system landscapes look like. For this reason, we follow the CDD (Conversation-Driven Development) approach here as well:
“Conversation-Driven Development (CDD) is the process of listening to your users and using those insights to improve your AI assistant. It is the overarching best practice approach for chatbot development. Developing great AI assistants is challenging because users will always say something you didn’t anticipate. The principle behind CDD is that in every conversation users are telling you-in their own words-exactly what they want. By practicing CDD at every stage of bot development, you orient your assistant towards real user language and behavior.”
Through the evaluation of the system, we are certain: LLMs can play out their advantages here in particular. Due to the extensive language base, they are able to deal with unforeseen events in a much more target-oriented way than rule-based approaches in the worst case. This case should also be controlled, but gains a certain degree of autonomy.
Added value of consulting services
Utilizing LLM-based AI in consulting for product advisory not only enhances the quality and breadth of services but also can lead to more innovative, timely, and cost-effective solutions for clients. However, it’s important to note that the human touch, ethical considerations, and deep contextual understanding that human consultants provide remain irreplaceable, and the LLMs could be seen as complementary tools rather than full replacements. Nevertheless here are a few advantages:
24/7 Availability
Unlike human consultants, LLMs can provide advisory services round the clock, enhancing the accessibility and convenience for clients across different time zones.
Scalability
LLM based AI can scale to handle a larger volume of queries or a growing client base without a proportional increase in operational costs.
Continuous Learning
With the right setup, LLMs can continuously learn from new data and feedback, improving the accuracy and relevance of the advice over time.
Improved Decision Support
The data-driven insights generated by LLMs can provide robust decision support to clients, aiding in risk assessment and strategic planning.
Thank you for the attention and time invested. If you want to learn more about the use case and its uses, the demo itself or the underlying technology, get in touch anytime via mail or LinkedIn.
The ZEW Contact Center 5.0, or CC5.0 for short, is a cloud-based solution developed by SUSI&James that alleviates the workload for companies that make frequent, recurring outbound calls. For example, appointment reminders, scheduling appointments, surveys, and similar tasks can be fully automated. With CC5.0, the voice assistant SUSI—who already serves as a digital employee across various industries—calls customers, patients, and business partners, thereby automating this process that is currently performed by humans. This means that, depending on demand, any number of calls can be routed simultaneously to the appropriate contacts. The advantage of this is that it saves both time and employee capacity. SUSI can learn individual dialogues and thus be flexibly deployed in various applications. To ensure that this application of SUSI functions particularly elegantly, robustly, and efficiently, the CC5.0 is based on the “EVA” AI platform from SUSI&James.
EVA is the first platform in the world dedicated to the development, training, and operation of digital employees. These digital employees are designed to interact logically with humans and communicate effectively. Through EVA, CC5.0 has access to various leading and cutting-edge technologies, such as a dialogue system, a machine learning framework, speech-to-text and text-to-speech components, as well as integration with a cloud communications provider to incorporate the voice assistant SUSI into the telephony system. Artificial intelligence (AI)-based digital assistants speak to respondents in natural language. CC5.0 enables the import of contact phone numbers and allows the voice assistant SUSI to systematically call these numbers using a pre-defined dialogue. This technology has the potential to relieve a large number of people and businesses by having SUSI automatically handle recurring outbound calls. Specifically, this proves very useful in the context of a telephone survey involving a large number of people.
The Research Collaboration
In this proof-of-concept project, we wanted to determine, through a field experiment conducted in collaboration with the Centre for European Economic Research (ZEW), whether voice assistants are suitable for use in opinion research, specifically for automated telephone surveys. The aim was to ascertain how the respondents' acceptance of the voice assistant compared to human interviewers. Furthermore, the project's objective was to use our SUSI system to automatically call numerous young companies in Germany and conduct a short survey on the topic of COVID-19. Crucially, this involved understanding how the pandemic has impacted the operations of German businesses. The implementation and analysis of this scenario took place over the past few weeks. This initial scenario served as an acceptance test for artificial intelligence and represented a breakthrough for the use of AI as a human-to-human interface. The CC5.0 product enabled ZEW to make multiple calls simultaneously and complete the entire survey within a short timeframe, instead of undertaking a large-scale project with a call center. For this to work, ZEW provided CC5.0 with the corresponding telephone numbers to be contacted. Furthermore, a pre-defined dialogue should already contain information that SUSI should request. In this regard, the ZEW had 500 registered companies with complete data including telephone number, managing director, and location.
With a single click, the CC5.0 automatically called all defined contacts, and the digital assistant SUSI independently conducted the survey using a sophisticated dialogue. First, she introduced herself and explained to the respondent what the survey was about and what role they played in it. She then continued with the pre-written dialogue, asking three simple questions that could be answered with “yes” or “no.” Specifically, the following questions were asked:
“Has the COVID-19 pandemic had a predominantly positive economic impact on your company so far?”
“Have you received or applied for assistance or support from the federal government, state governments, or local authorities for your business?”
“Are you considering changes to your strategic direction for the post-pandemic era, or are you already working on them?”
SUSI sammelte alle benötigten Daten im Gespräch und speicherte diese anonymisiert in einer sicheren Datenbank. Nachdem alle Umfragen abgeschlossen wurden, konnten die Ergebnisse eingesehen, ausgewertet und weiterverwendet werden. Hierbei wurde deutlich, dass ein solcher Prozess, wenn er von Menschen ausgeführt würde, eine sehr lange Zeit in Anspruch nähme. Aus diesem Grund bat das ZEW-Outbound-Projekt einen enormen Mehrwert und kann die Beziehung zwischen künstlicher Intelligenz und Menschen künftig verändern.