Durch langjährige Erfahrung im Testen von Komponenten, Fahrzeugen und Plattformen wissen wir, dass mit steigender Komplexität der Fahrzeuge auch die Anforderungen an die Fahrzeugerprobung und die Testfahrer gestiegen sind. Testfahrer sind herausgefordert, während der Versuchsfahrt Beanstandungen möglichst detailliert festzuhalten, die Fahrten zeitnah abzuschließen und dabei – selbstverständlich – sicher ans Ziel zu gelangen.
Unser KI-gestützter Beifahrer sorgt für einen qualitativ hochwertigen Austausch von Informationen ohne Datenverlust in Echtzeit. Der Fahrer tauscht relevante Informationen im natürlichen Dialog mit der KI aus: Fahrmanöver werden angeleitet und dokumentiert, während der Erprobungsfahrt werden Auffälligkeiten erfasst, Details entlang eines Fehlerbaumes aufgenommen und die Daten in Erprobungssystemen in Echtzeit dokumentiert.
Durch unseren KI-gestützten Beifahrer erhöht sich die die Datenqualität deutlich bei Entlastung des Fahrers und damit höherer Sicherheit, während die Prozessgeschwindigkeit steigt bei reduzierten Kosten.
„Uns erreichen hunderte Anrufe pro Tag und besonders in dieser außergewöhnlichen Zeit ist die Unterstützung durch SUSI pures Gold. Sie bietet uns einen erheblichen Mehrwert.“ Unsere Digitale Mitarbeiterin SUSI übernimmt in der Arztpraxis von Dr. Eckermann und Bauer die Telefonanrufe. Dabei werden die Anliegen der Betroffenen erfasst und für die Mitarbeitenden aufbereitet.
„Unsere Mitarbeitenden sind durch diese KI-Lösung entlastet und unsere Praxis ist immer verfügbar für unsere Anrufer. Das gibt uns ein tolles Gefühl.“
Durch die Synchronisierung der Wertschöpfungsprozesse moderner Supply Chains sind Unterbrechungen des Regelablaufs der Logistik mit hohen Aufwänden, Zeitverlusten und Folgekosten verbunden, oft entlang der gesamten Lieferkette bis zur Produktauslieferung. Da trotz 0-Fehler-Ansatz immer wieder Unterbrechungen vorkommen, ist es entscheidend, Probleme schnell und umfänglich zu erfassen, um eine Lösung zielgerichtet und kurzfristig zu generieren und in den Einsatz zu bringen.
Hier spielt unsere KI ihre Vorteile aus. Bei SUSI können Probleme 24/7 im natürlichen Dialog gemeldet werden. Ob am Telefon oder per Chat, sie erfasst die Problemstellung, führt einen dynamischen Fehlerdialog, dokumentiert im Kundensystem und löst Workflows in Echtzeit aus. Hierdurch werden beispielsweise Lieferverzögerungen transparent und automatisch berücksichtigt, der Prozess bei Transportschäden automatisch in Gang gesetzt oder Fehlmengen gemeldet und ausgeglichen.
Dabei ist die Problemmeldung schnell und unkompliziert, die Daten sind vollständig und – weil SUSI immer im Einsatz ist – verkürzt oder vermeidet sie absolut verlässlich die Dauer schädlicher Sonderprozesse.
Heutzutage sind in der Produktion und Lagerung smarte Intralogisitklösungen unabdingbar. Warenströme müssen effizient in Versorgungsketten eingespeist und Güter im Versand schnell abgewickelt werden. Unser Kunde MFI Innovations bietet hierfür unterschiedlichste Einzel- und Gesamtlösungen an und setzt im telefonischen Service für KundInnen unser SmartOffice ein.
Tritt bei den Industriekunden der MFI ein Fehler auf, kann es Rund um die Uhr zu kritischen Stillständen der Intralogistik kommen. Derartige Ausfälle können bei fehlendem Support sehr teuer werden, weshalb MFI Innovations ihren KundInnen entsprechende Service- und Dienstleistungspakete anbietet, um auch im Krisenfall den Rücken freizuhalten.
Rufen betroffene Unternehmen den Kundenservice von MFI an, erreichen Sie entweder direkt eine technische Fachkraft für den Service oder, sollte diese gerade nicht verfügbar sein, unser SmartOffice. Dort können unmittelbar die Problematik und Relevante Fehlercodes gemeldet werden, sodass MFI Innovations schnellstmöglich ihren Supportprozess auslösen kann.
Die technische Fachkraft kann sich mit den bereits aufgenommen Informationen unmittelbar bei Wiederverfügbarkeit ein Bild von der Situation machen, diese Voranalysieren und im besten Fall dem Unternehmen schon direkt beim ersten Rückruf eine Lösung präsentieren.
Durch langjährige Erfahrung im Testen von Komponenten, Fahrzeugen und Plattformen wissen wir, dass mit steigender Komplexität der Fahrzeuge auch die Anforderungen an die Fahrzeugerprobung und die TestfahrerInnen gestiegen sind. TestfahrerInnen sind herausgefordert, während der Versuchsfahrt Beanstandungen möglichst detailliert festzuhalten, die Fahrten zeitnah abzuschließen und dabei – selbstverständlich – sicher ans Ziel zu gelangen.
Unsere KI-gestützten Beifahrenden sorgen für einen qualitativ hochwertigen Austausch von Informationen ohne Datenverlust in Echtzeit. Der Fahrende tauscht relevante Informationen im natürlichen Dialog mit der KI aus: Fahrmanöver werden angeleitet und dokumentiert, während der Erprobungsfahrt werden Auffälligkeiten erfasst, Details entlang eines Fehlerbaumes aufgenommen und die Daten in Erprobungssystemen in Echtzeit dokumentiert.
Durch unsere KI-gestützten Beifahrenden erhöht sich die Datenqualität deutlich bei Entlastung der Fahrenden und damit höherer Sicherheit, während die Prozessgeschwindigkeit steigt bei reduzierten Kosten.
Das Telefonaufkommen in Rechtsanwaltskanzleien überschreitet die Verfügbarkeit der Mitarbeitenden im Sekretariat. Eine besondere Herausforderung besteht darin, dass das Telefonaufkommen zyklischen Schwankungen unterliegt. In Spitzenzeiten bleiben somit viele Anrufe unbeantwortet. Ohne die Digitale Mitarbeiterin SUSI mussten Sekretariate das Anliegen der Anrufenden in zeitintensiven Gesprächen aufnehmen und stichpunktartig an die entsprechende Rechtsvertretung zur Bearbeitung weiterleiten.
Seit dem Start der Zusammenarbeit unterstützt SUSI Mitarbeitende des Sekretariats. Sie übernimmt alle Anrufe, welche vom Team des Sekretariats nicht bearbeitet werden können. Im Gespräch nennt der Anrufende den Grund des Anrufs und die KI klassifiziert das Anliegen. In Abhängigkeit des erkannten Themas stellt SUSI gezielte Rückfragen, oder beantwortet die Frage des Anrufenden sofort.
Anschließend sendet sie eine Zusammenfassung inklusive abgefragten Aktenzeichen an die entsprechende Abteilung oder direkt an die betroffene Rechtsvertretung. SUSI informiert zudem den Anrufenden, welche Dokumente bereits im Vorfeld an die Kanzlei gesendet werden können. Dies reduziert die Zahl der Rückrufe und minimiert die Durchlaufzeit.
Das Energieversorgungsgeschäft ist stark von saisonalen Ereignissen geprägt. Preiserhöhungen, Rechnungsversand oder neue Energiepauschalen sorgen dafür, dass viele KundInnen in einem sehr kurzen Zeitraum Kontakt zum Energieversorgungsunternehmen aufnehmen. Das eingehende Telefonaufkommen ist in Zeiten von Fachkräftemangel und der ohnehin schon enormen Arbeitslast nicht immer abzufangen.
Die Digitale Mitarbeiterin SUSI bringt im Rahmen des SmartOffice die nötigen Skills und Erfahrungen mit, um Energieversorgungsunternehmen und andere öffentliche Betriebe direkt zu unterstützen. Sie übernimmt den gesamten Anrufüberlauf und kümmert sich um eine vom Anliegen abhängige Weiterleitung. Bei kritischen Anliegen, wie einer Gasstörung, leitet sie das Gespräch direkt telefonisch an die Störmeldezentrale weiter.
Durch die fallabschließende Verarbeitung von Zählerständen, Abschlagsanpassungen oder Rechnungsänderungen gewinnen die Mitarbeitenden Zeit, welche sie in die betreuungsintensiveren Gespräche mit KundInnen investieren können.
The artificial intelligence-based digital employee SUSI from SUSI & James GmbH takes over and optimizes a wide variety of communication-heavy business processes in companies. SUSI ensures 24/7 that no call goes unanswered and takes all calls. With its support, SUSI creates space and time for service-intensive issues. Employees can once again concentrate fully on value-adding activities.
In this article, we highlight the use of SUSI as a Digital Product Advisor.
We show how to combine traditional NLP with the power of LLMs and Generative AI in a way that ensures the best possible customer experience.
The following demo is about a consultation between a digital employee and a user who is interested in buying a new car. SUSI guides the user through a three-step process in which general information about the desired vehicle can first be provided. Then, based on a suggested selection of eligible vehicles, the user can learn more about these vehicles by asking specific questions. Once the user has decided on one or more vehicles, the last step is to arrange a test drive or a purchase appointment.
Step 0 — Preparing the data and make some basic considerations
The basis for product consulting are products, in this case about 7000 current vehicles, which are available in JSON format. (Displayed simplified in this example){ „name“: „A3“, „car_model_id“: 82, „car_trim_id“: 25295, „car_series_id“: 2901, „car_production_year“: „2016“, „car_series_name“: „Sportback Schrägheck 5-Tür“, „car_trim_name“: „1.2 TFSI MT (105 ps)“, „car_specifications“: { „Anzahl der Gänge“: „6“, „Schadstoffeinstufung“: „EURO V“, „Fahrzeugart“: „Schrägheck“, „Sitzplätze“: „5“, „Breite“: „1785“, „Radstand“: „2636“, „Spur vorne“: „1535“, „Kofferraumvolumen minimal“: „380“, „Kofferraumvolumen maximal“: „380“, „Spur hinten“: „1506“, „Kraftstoffe“: „Benzin“, „Hubraum“: „1197“, „Wendekreisdurchmesser“: „10.9“, „Zuladung“: „485“, „Anhängelast (gebremst)“: „3240“, „Ladehöhe“: „677“ }, „car_options“: { „Attraction“: [ „Elektromechanische Servolenkung mit variabler Kraft auf das lenkrad“, „Servotronic (aktives lenkrad)“, „Schallschutz Verglasungen“, „Start-stop-System“, „Mechanische Vordersitze einstellen“, ], „Ambiente“: […], „Ambition“: […] }, „manufacturer“: „Audi“ }
When developing a Retrieval or Retrieval Augmented Generation (RAG) approach for a dataset containing detailed car (or any other product) information, it’s crucial to consider various factors to ensure an effective and accurate system. Here’s a breakdown of the aspects to consider:
Understanding the Data Structure
Understanding the dataset’s structure is foundational. The given dataset is in a structured format with nested fields and especially mixed data types, which requires a clear understanding to accurately retrieve or generate the necessary information. Special consideration should be given to the fact that, depending on the heterogeneity of the data points, aspects such as the presence of contextual information,digits, and mixed data must be taken into account, especially when vectorizing.
Indexing Strategy
Proper indexing is crucial for effective retrieval. Consider using a robust indexing strategy to ensure quick and accurate retrieval of car details based on various parameters such as car model, production year, or manufacturer.
Query Formulation
The query formulation should be designed to handle a variety of search terms and parameters. It should be robust enough to accommodate different types of queries and return relevant results.
Retrieval-Augmented Generation
For RAG, integrating retrieval mechanisms with generation models requires a seamless flow of information. Ensure that the retrieval process can feed relevant data to the generation model to facilitate meaningful output. Special attention should also be paid here to the question of the target language, since capable LLMs do not function well multilingually in every case.
Evaluation Metrics
Establishing evaluation metrics is necessary to measure the performance of the retrieval and generation systems. Metrics could include accuracy, recall, precision, and F1 score among others. To perform a qualitative analysis of the entire scope, individual metrics are usually inadequate. Frameworks like Ragas can fill this gap.
Scalability
The system should be designed to handle scalability to accommodate growing data or increased query loads without compromising performance.
The Haystack framework and the SmartOffice form the basis for the above steps. In the example shown, it quickly becomes clear that an initial selection of vehicles to be proposed can and should be based on a number of metadata such as manufacturer, fuel consumption and number of seats.
Since a classic document is represented in Haystack as follows:class Document: content: Union[str, pd.DataFrame] content_type: Literal[„text“, „table“, „image“] id: str meta: Dict[str, Any] score: Optional[float] = None embedding: Optional[np.ndarray] = None id_hash_keys: Optional[List[str]] = None
the question quickly arises as to which JSON content is defined as content on which textual embeddings will later also be generated and which data will become part of the meta-data.
As for the choice of database (or DocumentStore), we compared Weaviate and ElasticSearch. Both systems offer similar advantages and disadvantages, especially the advanced filter logic in the case of ElasticSearch tipped the scales for prototyping.
Step 1 — Designing Prompts for Basic Retrieval
In this step, the focus is on the question of how to derive and extract from almost arbitrary natural language statements the criteria on which meaningful filtering can be performed.
Step 1: General description of the car and its parameters
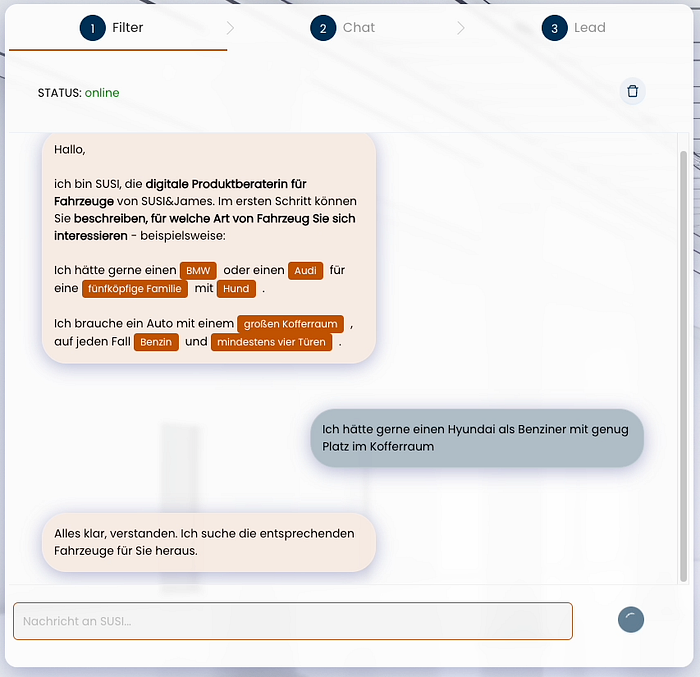
The statement pictured in SUSI’s introduction translates as:
„I’d like a BMW or an Audi for a family of five with a dog.“
The filter we need to construct from this in Haystack-compatible format looks like this:{ „$and“: { „number_of_seats“: { „$eq“: 5 }, „trunk_volume_minimum“: { „$gte“: 400 }, „manufacturer“: { „$in“: [ „BMW“, „Audi“ ] } } }
For this problem, we evaluated several approaches, including:
Text2SQL approach which refers to a type of natural language processing (NLP) approach that translates natural language queries into SQL (Structured Query Language) queries.
Span extraction approach which refers to a task in Natural Language Processing (NLP) where the goal is to identify and extract a specific portion of text, referred to as a “span,” from a larger body of text based on a given query or condition.
Generative approach which refers to the assumption that large language models given a specifying prompt have sufficient knowledge about identifying and extracting specific information from a given text to be able to satisfy the aforementioned requirement in the form of generated output.
After a short prototyping phase of the mentioned approaches, we decided to use the generative approach. The shortlisted models were:
After a prompt engineering phase, the following prompt proved to be a good fit (partially shown here):I need you to create a json serialized python dictionary as string that is derived from a user input.
In the user input there are filter criteria that can be expressed in different ways. The user can express himself on the following parameters:
The following logical operators are available: $and, $or
The following comparison operators are available: $eq, $in, $gt, $gte, $lt, $lte
The GPT-4 and Falcon-180B models have shown similar performance quality, which is why we have implemented both methods in a configurable way. The outcome looks like:
Step 1: Result with eligible cars bases on the user input
It should be mentioned that the biggest challenge was to get the models to reliably produce structured output in JSON format. In the meantime, there are various approaches to this problem, which we have not dealt with further in the scope of this processing. It should also be mentioned that while the LeoLM model did not quite provide the required result in this case, it has proven to be very capable in other experiments, such as extracting personal data from a text.
Step 2 — Designing Prompts for Advanced Retrieval and Question Answering
In this step, the focus is on a consultation regarding the pictured vehicles (and also additional ones not pictured). The user should intuitively and colloquially ask questions or discuss ideas that will help him/her select specific vehicles.
Step 2: Consultation regarding the pictured vehicles
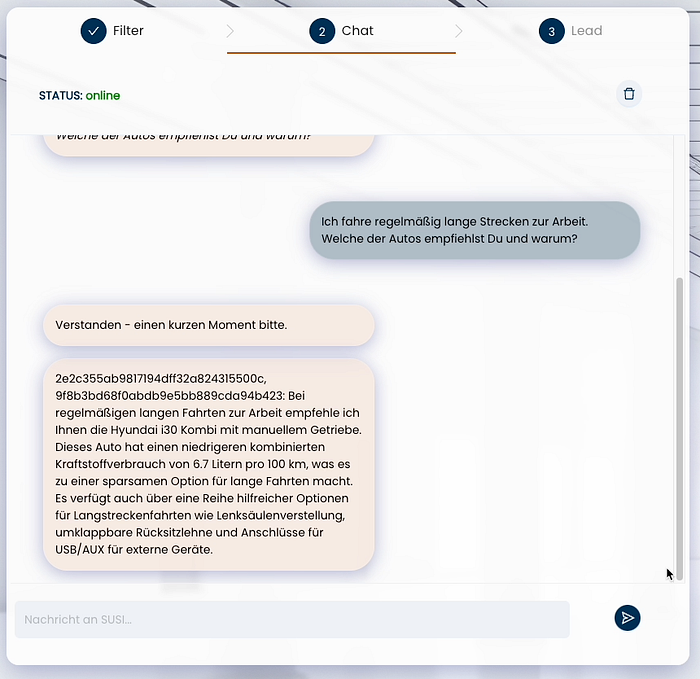
The statement pictured in SUSI’s introduction translates as:
“I regularly drive long distances to work. Which of the cars do you recommend and why?”
In this statement, representative of the presented form of expected user input, there are several challenges at once.
As already visible in Step 1, there is no parameter in the data basis that reads: “suitable_for_long_distances”. Even if there were, the question of qualification to this suitability would arise. The user’s expectation is different: “I don’t know exactly what parameters need to be considered to make a vehicle suitable for long trips, so I hope (or expect) that YOU know.”
In the second part of the statement, the user unconsciously (sometimes consciously) provides the context of the vehicles to be considered by using the term “of the (mentioned) cars”. At this point, we use the demonstrable power of the RAG procedures, in two ways:
We instantiate an agent that handles the communication with the user. The advantage of the agent is a persistent memory, which is made available as a previous conversation history to the processing of the user input. Thus, the model is aware of the context when referring to information in the previous conversation by the user.
We then give the agent various tools such as retrieving data from the Elastic Cluster and checking information on the Internet, and of course the basis of judgment: the vehicles and their data, and then try to let the model capture the relationship between the user input and the data at hand by clever prompting:Below you will find information about vehicles, such as their length, weight and equipment. Each vehicle has its own line and each line begins with the vehicle id. The information has the scheme „attribute_descriptor: attribute_value;“ except for the options. These are under „Optionen“ and are listed as packages with the schema „_package_descriptor_: list_of_comma_separated_attributes“. {car_description} Under the vehicle information you will find the question of a user. Answer the question as best you can, based solely on the vehicle information. Write the answer in German. If you can’t find the answer based on the information, please let us know. Every answer should have the format: „vehicle_id (or vehicle_ids comma separated): textual_response“, except if the user expresses an interest in buying or test driving the product, you will output „%smartoffice#vehicle_id or comma separated vehicle_ids#kind_of_interest%“ (where kind_of_interest is either test_drive or buy_vehicle) as the response. It is possible that the user asks questions or statements with a reference to the previous course of the conversation, which you can find here: {history} Your answers should take this conversation history into account, if appropriate and necessary. Question: {query} Response:
Step 2: Response from the RAG approach
The response in the image translates to:
“For regular long trips to work, I recommend the Hyundai i30 station wagon with manual transmission. This car has a low combined fuel consumption of 6.7 liters per 100km, which makes it an economical option for long trips. It also has a number of helpful options for long distance driving such as steering column adjustment, folding rear seat back and ports for USB/Aux for external devices.”
This is exactly the behavior that we hope for or imagine from our digital employees. The response not only addresses the focus of the user’s input, but also provides additional information that is considered helpful to the user.
This time the result was more difficult to judge. While GPT-4 stood out positively in terms of “consulting performance”, the interpretation of user input in terms of “parameters to be taken into account” or the direct answering of questions was clearly better in Falcon-180B from our point of view.
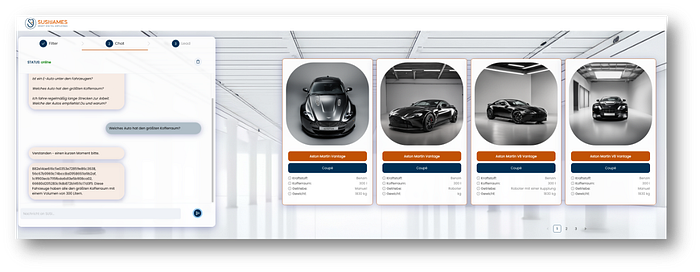
Step 2: Follow up questions to a given set of cars
The difficulty was, and still is, primarily in correctly capturing the task that is generated from the interpretation of the user input and letting it flow into the prompt.
The question and the response in the image translate to:
Q: “Which of the vehicles has the largest trunk?”
A: “These vehicles have the largest trunk with a volume of 300 liters.”
Similar to the example just given, there is an implicit reference to the vehicles defined as the result set in the previous step. The character of the user’s question is reminiscent of a classic example of automated question answering. The complexity of the question is much lower than the previous one because of the level of inference we expect from the model in terms of deliberative conversation.
Step 3 — Handing over to the SmartOffice
At this step, the user has gone through the process to the point where there is either an interest in purchasing or an interest in test driving one of the vehicles. At this point, one could rightly think about the further use of an agent-based solution, but in the corporate context we rely on our SmartOffice product, as it already solves a large part of the existing challenges in a sensible and efficient way.
Step 3: Handover of the user to the guided dialog
The introduction in the image translates to:
“Hello,
I am SUSI, the digital employee of SUSI&james car dealership. I understand that this is about a test drive of the vehicles “Huyndai i40 1.6 MT (135HP)”. In the following I need to ask some personal information for this.
Do you agree with this?”
The conversation then continues as follows:
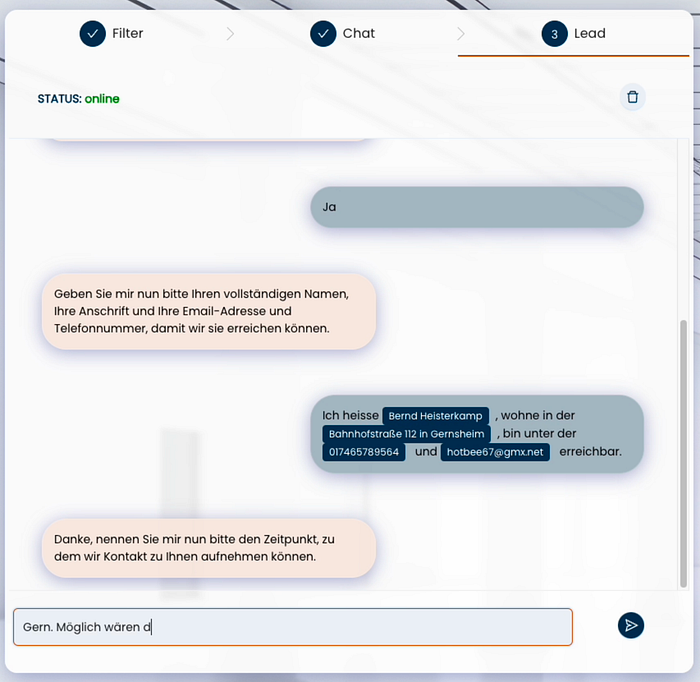
Step 3: Continuous processing through the SmartOffice
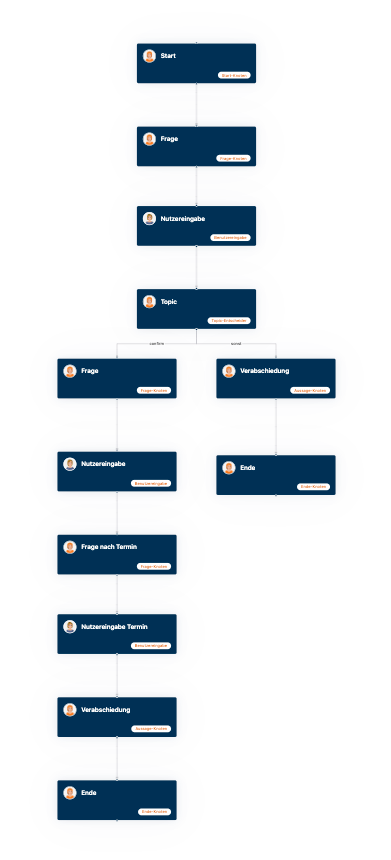
SUSI in SmartOffice needs to collect various information to make an appointment for a test drive. This information is requested in the course of the conversation, and queries are asked if necessary. In this case, this is not not done by an “autonomous” agent, but around the NLU core of the SmartOffice, orchestrated by predefined dialogs, as shown in the following image:
Step 3: A dialog created with the DialogBuilder of SmartOffice
SmartOffice processes all the information obtained during the call and can subsequently provide it for further processing in various ways, e.g. in the form of an API call, a mail or an outgoing call.
The path shows how a consultation with predefined interest can turn into a potent lead in a sales pipeline. For reasons of comprehensibility, the procedure shown is divided into several steps. It is of course also conceivable (and we have also evaluated this) to greatly simplify this process.
Learnings
In our view, the topic of product advice is challenging even in the very current technology space with Question Answering, Retrieval Augmented Generation, Autonomous Agents and Conversational AI. The main reason for this is certainly that we are not dealing with classic, general conversations with a simple question-answer process, but with complex, multi-layered dialog logic.
The following striking features and learnings are worth mentioning at this point:
Modular architecture based on LLM
When designing the product consultation, we wanted to take into account that the product base may change. In one case it might be vehicles, in the next it could be medicines or beauty products. For this reason, all components that are use-case specific are designed as modules (the database, the prompts, …), so that an exchange and an adaptation are possible intuitively and with little time effort.
LLM vs “traditional approaches”
In the steps shown, it was obvious not to commit to a single technology approach, but to decide in a fine-grained way which solution path is suitable for which problem. While “traditional” approaches such as entity extraction and possibly even syntax parsing promise a certain degree of security through reproducibility and control, they are relatively costly — for example, due to the use-case specific adaptations. Using Large Language Models, on the other hand, works intuitively even in the first approach, and if you have either the hardware or the necessary financial resources, you will have qualitative results very quickly. In fact, one should not make the mistake of considering the topic of “prompt engineering” as “solved”. Even minor changes decide the value of the output and should be well considered. In addition, the currently popular question arises in any case whether one should finetune an LLM in relation to the usecase or whether one should choose a RAG approach, for example. Here, too, requirements such as a clean data basis, training resources and time quickly pose a hurdle.
Unpredictability of user input
During the testing of the system shown and also of SmartOffice in general, we noticed that we often only think we know what the concerns of users are and that we can only assume what inputs in system landscapes look like. For this reason, we follow the CDD (Conversation-Driven Development) approach here as well:
“Conversation-Driven Development (CDD) is the process of listening to your users and using those insights to improve your AI assistant. It is the overarching best practice approach for chatbot development. Developing great AI assistants is challenging because users will always say something you didn’t anticipate. The principle behind CDD is that in every conversation users are telling you-in their own words-exactly what they want. By practicing CDD at every stage of bot development, you orient your assistant towards real user language and behavior.”
Through the evaluation of the system, we are certain: LLMs can play out their advantages here in particular. Due to the extensive language base, they are able to deal with unforeseen events in a much more target-oriented way than rule-based approaches in the worst case. This case should also be controlled, but gains a certain degree of autonomy.
Added value of consulting services
Utilizing LLM-based AI in consulting for product advisory not only enhances the quality and breadth of services but also can lead to more innovative, timely, and cost-effective solutions for clients. However, it’s important to note that the human touch, ethical considerations, and deep contextual understanding that human consultants provide remain irreplaceable, and the LLMs could be seen as complementary tools rather than full replacements. Nevertheless here are a few advantages:
24/7 Availability
Unlike human consultants, LLMs can provide advisory services round the clock, enhancing the accessibility and convenience for clients across different time zones.
Scalability
LLM based AI can scale to handle a larger volume of queries or a growing client base without a proportional increase in operational costs.
Continuous Learning
With the right setup, LLMs can continuously learn from new data and feedback, improving the accuracy and relevance of the advice over time.
Improved Decision Support
The data-driven insights generated by LLMs can provide robust decision support to clients, aiding in risk assessment and strategic planning.
Thank you for the attention and time invested. If you want to learn more about the use case and its uses, the demo itself or the underlying technology, get in touch anytime via mail or LinkedIn.
Das ZEW Contact-Center 5.0, kurz CC5.0, ist eine von SUSI&James entwickelte Cloud-Lösung und entlastet Unternehmen, welche ständig wiederkehrende, ausgehende Anrufe durchführen. So lassen sich beispielsweise Terminerinnerungen, Terminvereinbarungen, Umfragen oder Ähnliches vollständig automatisieren. Beim CC5.0 telefoniert die Sprachassistentin SUSI, die bereits als Digitale Mitarbeiterin in verschiedenen Branchen agiert, mit Kunden, Patienten und Partnern der Unternehmen und automatisiert somit diesen heute menschlich ausgeführten Prozess. Dies bedeutet, dass je nach Bedarf, entsprechend beliebig viele Anrufe auch parallel an entsprechende Kontakte ausgesteuert werden können. Der Vorteil davon liegt darin, dass einerseits viel Zeit und andererseits Mitarbeiterkapazität eingespart wird. SUSI kann individuelle Dialoge erlernen und somit flexibel in unterschiedlichen Anwendungen zum Einsatz kommen. Damit diese Anwendung von SUSI besonders elegant, robust und leistungsfähig funktioniert, basiert das CC5.0 auf der KI-Plattform „EVA“ von SUSI&James.
EVA ist die erste Plattform global, die für die Entwicklung, das Training sowie den Betrieb Digitaler Mitarbeiter verantwortlich ist. Diese Digitalen Mitarbeiter werden darauf ausgerichtet, mit dem Menschen logisch interagieren und sprechen zu können. Durch EVA hat das CC5.0 Zugriff auf verschiedene leading- und cutting-Edge Technologien, beispielsweise ein Dialogsystem, ein Machine-Learning Framework, Speech-to-Text und Text-to-Speech Komponenten, sowie die Integration in einen Cloud Kommunikationsanbieter zur Einbindung der Sprachassistentin SUSI in die Telefonie. Auf künstlicher Intelligenz (KI) basierte digitale Assistenten sprechen mit den Befragten in natürlicher Sprache. Das CC5.0 ermöglicht es, Telefonnummern von Kontakten zu importieren und diese systematisch durch die Sprachassistentin SUSI mit einem vorgefertigten Dialog abzutelefonieren. Diese Technologie hat das Potenzial eine große Anzahl von Menschen und Unternehmen zu entlasten, indem ständig wiederkehrende, ausgehende Anrufe automatisch von SUSI durchgeführt werden. Konkret macht sich das im Beispiel einer Telefonumfrage mit einer großen Anzahl von Menschen sehr zu nutzen.
Die Forschungskooperation
In diesem Proof-of-Concept Projekt wollten wir im Rahmen eines Feldexperiments gemeinsam mit dem Zentrum für Europäische Wirtschaftsforschung (ZEW) herausfinden, ob sich Sprachassistenten für den Einsatz in der Meinungsforschung im Hinblick auf automatisierte, telefonische Befragungen eignen. Hierbei galt es herauszufinden, wie sich die Akzeptanz der befragten Personen, gegenüber dem Sprachassistenten im Vergleich zum Menschen verhielt. Des Weiteren war das Ziel des Projektes mit unserer SUSI eine Vielzahl junger Unternehmen in Deutschland automatisch anzurufen und eine kurze Umfrage zum Thema Corona durchzuführen. Wichtig dabei war herauszufinden, wie sich die Corona-Pandemie auf den Betrieb deutscher Unternehmen ausgewirkt hat. Die Durchführung und Auswertung des Szenarios sind in den letzten Wochen geschehen. Dieses erste Szenario galt als Akzeptanztest für das Thema künstliche Intelligenz und war ein Durchbruch für den Einsatz von KI als Schnittstelle zum Menschen. Das Produkt CC5.0 ermöglichte es der ZEW mehrere Anrufe gleichzeitig zu tätigen und innerhalb eines kurzen Zeitraumes mit der gesamten Umfrage abzuschließen, statt ein umfangreiches Projekt mit einem Callcenter durchzuführen. Dazu brauchte das CC5.0 seitens der ZEW entsprechende Telefonnummern, die kontaktiert werden sollten. Außerdem sollten in einem vorgefertigten Dialog bereits Informationen gegeben sein, die SUSI erfragen sollte. Diesbezüglich hatte das ZEW 500 registrierte Unternehmen mit vollständigen Daten inklusive Telefonnummer, Geschäftsführer und Standort vorliegen.
Mit einem Klick rief das CC5.0 automatisch alle definierten Kontakte an und die Digitale Mitarbeiterin SUSI führte anhand eines ausgefeilten Dialogs die Umfrage selbstständig durch. Zunächst stellte sie sich vor und erläuterte dem Gesprächspartner, worum es sich handelte und welche Rolle dieser für die Umfrage spielte. Danach führte sie den vorgefertigten Dialog fort und stellte dabei drei einfache Fragen, auf die mit „Ja“ oder „Nein“ geantwortet werden konnte. Konkret wurden folgende Fragen gestellt:
“Hat die Corona-Pandemie bis zum jetzigen Zeitpunkt für Ihr Unternehmen überwiegend positive wirtschaftliche Auswirkungen?”
“Haben Sie für Ihr Unternehmen Hilfe oder Unterstützung des Bundes, der Länder oder Kommunen in Anspruch genommen oder beantragt?”
“Denken Sie über Veränderungen Ihrer strategischen Ausrichtung für die Zeit nach der Corona-Pandemie nach oder arbeiten Sie bereits daran?”
SUSI sammelte alle benötigten Daten im Gespräch und speicherte diese anonymisiert in einer sicheren Datenbank. Nachdem alle Umfragen abgeschlossen wurden, konnten die Ergebnisse eingesehen, ausgewertet und weiterverwendet werden. Hierbei wurde deutlich, dass ein solcher Prozess, wenn er von Menschen ausgeführt würde, eine sehr lange Zeit in Anspruch nähme. Aus diesem Grund bat das ZEW-Outbound-Projekt einen enormen Mehrwert und kann die Beziehung zwischen künstlicher Intelligenz und Menschen künftig verändern.